
Download
Listen
Figure 2: Connectivity inside a data centre is divided into three layers


This article outlines how connectivity within a data centre and between multiple data centres is evolving, the emerging architectures and key implications for ecosystem players.
As data centres scale to support new generations of AI and cloud workloads, the role of connectivity is becoming increasingly important to AI performance. While power availability and access to advanced compute continue to shape facility design, connectivity now plays an equally critical role. Networks that move data within and between sites determine how efficiently workloads can interact and how effectively the environment performs.
Intra–data centre connectivity refers to the high-speed network fabric inside a facility that links servers, storage, and increasingly large GPU clusters. Data centre interconnect (DCI) refers to the fibre and optical transport networks that connect multiple data centres – across campuses, metros and regions – to enable distributed workloads and resilience.
Figure 1: Connectivity is critical within and between data centres

Source: STL Partners
Inside individual data centres, AI workloads are reshaping how traffic flows and how network fabrics are engineered, driving far greater east–west traffic and tighter coordination between accelerators. At the same time, the growing distribution of training, fine-tuning and inference across regions is placing new demands on the links between facilities. Connectivity has always been central to data centre design, but AI is expanding its role. These trends are now pushing operators to evolve their network architectures so that connectivity can support far more complex and distributed workloads.
This article outlines how intra- and inter-data centre connectivity are evolving, the architectural approaches emerging in response, and the implications for data centre operators, telecom providers, and investors.
Intra data centre connectivity
At the core of the intra data centre connectivity evolution is a transformation in how AI workloads operate. Unlike traditional cloud workloads, training an AI model requires thousands of GPUs to continuously exchange results and updates with each other in near real-time. Traditionally, where most data flowed in or out of the data centre (“north-south traffic”), today’s massive AI models create vast “east-west traffic”— with trillions of data points being transferred between servers inside the data centre itself.
This shift has required a rethink in network architecture. The industry standard now is to separate conventional front-end traffic from the ultra-demanding back-end connectivity that links GPUs together.
• The front-end network handles everyday business tasks and connects users, storage and servers — managing standard workloads and internet traffic.
• The back-end network operates with three to four times the bandwidth of traditional networks and is built for microsecond level latency. It is further divided into two networks:
– The scale-up network is designed for ultra-fast data exchange between GPUs and accelerators within the same cluster or “pod”; it uses specialised technologies like NVLink or UALink to connect to 1,024 accelerators supporting very high bandwidth and extremely low delays for tightly coordinated AI operations.
– Finally, the scale-out network links multiple clusters or pods across the wider data hall using high-speed ethernet and fibre, making sure all the clusters can work together smoothly even as facilities scale up to tens of thousands of GPUs.
In short, the front-end handles general access; scale-up enables deep cooperation within a pod; and scale-out supports communication between pods, ensuring the entire infrastructure operates without bottlenecks as AI workloads grow.
Figure 2: Connectivity inside a data centre is divided into three layers

Source: STL Partners
To achieve this, most new facilities rely on “spine-leaf” topology. In this topology, any two servers can communicate with just one or two steps – known as hops. Fewer hops help reduce delays, ensure workloads do not get stuck in traffic, and allows scaling as more GPUs are added. Spine-leaf networks also minimise oversubscription, which is the amount of bandwidth servers must share with each other. Older designs may have had three or five servers sharing the same link (ratios such as 3:1 or 5:1). Modern AI data centres aim for a 1:1 ratio so each GPU gets full bandwidth and does not have to wait for data.
The tools powering this transition are evolving rapidly. For communication between GPUs inside a single server or rack, ultra-fast interconnects like NVIDIA’s NVLink help GPUs instantly share large amounts of data. But when GPUs are in different racks, they use network technologies built for speed and efficiency. One important method here is Remote Direct Memory Access (RDMA), which enables a GPU to directly read or write data in another GPU’s memory, without having to pass through the server’s CPU or deal with traditional bottlenecks. When RDMA is implemented over ethernet (known as RoCE), it eliminates latency overheads, keeping GPUs fully utilised and workloads moving seamless. RDMA is essential because it dramatically reduces the time taken to move data – eliminating unnecessary steps and network delays – so GPUs can work together seamlessly, keeping AI workloads running at their maximum possible speed and efficiency. Without RDMA, the transfer of data between chips would be much slower, causing expensive resources to sit idle while waiting for information to arrive.
In summary, AI places much heavier demands on data movement inside the data centre, so the design of the network fabric has a major role in how effectively a data centre operates. Facilities that prioritise direct, lossless GPU-to-GPU connectivity will be positioned to support the AI workloads reshaping global industries. Those that do not will risk falling behind.
Data centre interconnect
As AI models grow in complexity and scale, training and inference workloads increasingly span multiple sites, across metros, countries and continents. This shift is redefining the role of data centre interconnect (DCI) into a strategic capability that determines whether AI infrastructure can scale efficiently and resiliently. In the past, DCI networks were designed primarily for predictable cloud workloads: replication, backup, and routine traffic between a handful of core sites. Those patterns were largely symmetrical and stable over time. But AI breaks this model. According to STL Partners’ research, each megawatt of AI compute now generates up to twice the DCI throughput of traditional cloud capacity, and traffic is increasingly multi-directional, bursty, and distributed. These bursts can be large and unpredictable, forcing operators to overprovision bandwidth to avoid bottlenecks — and raising important questions about how vendors price capacity that may only be fully used during peak training moments.
AI workloads are inherently distributed — they move across data centres as models evolve from training to deployment. A single model may be trained in one region, fine-tuned in another, and deployed for inference in dozens of regional facilities. As those models learn and adapt, they constantly exchange data, synchronise parameters and share updates across the DCI fabric. Traditional hub-and-spoke architectures, where everything flowed through a central core, simply cannot manage this multidirectional movement. The industry is therefore pivoting toward mesh-style network topologies that connect data centres directly to one another, allowing traffic to take the most efficient path between sites rather than backhauling through a single hub.
Figure 3: DCI network architecture must evolve to incorporate multi-directional flows
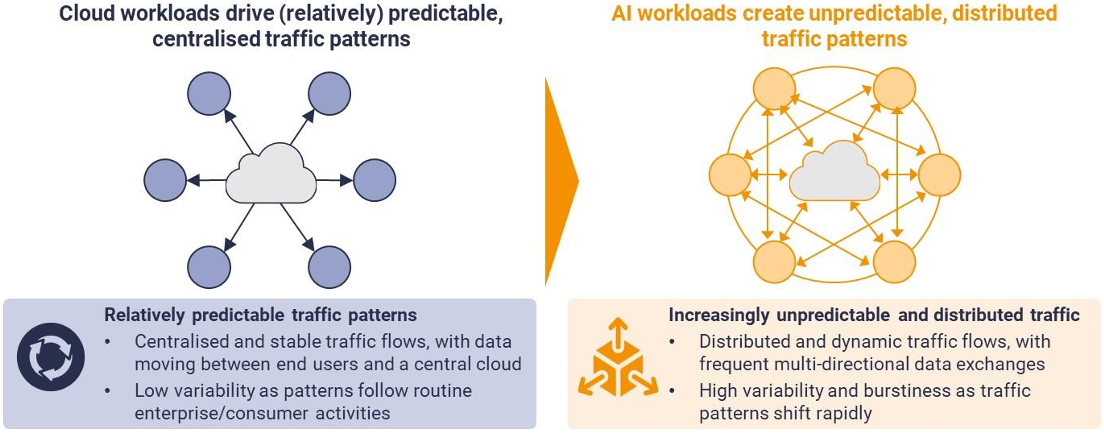
Source: STL Partners
This evolution is as much about flexibility as capacity. Fixed-bandwidth interconnects struggle to accommodate AI’s unpredictable peaks and troughs. When a new model goes viral or a training run scales up overnight, static contracts lead to over-provisioning during quiet periods and congestion at peak demand. To solve this, operators are increasingly adopting Network-as-a-Service (NaaS) models that allow bandwidth to scale dynamically in line with real-time workload needs. Under NaaS, capacity can be spun up or down to meet demand in real time, turning DCI into an elastic, on-demand resource rather than a fixed pipe.
DCI evolution is also being shaped by geopolitical, regulatory and market forces that influence where data can move and how networks are designed. Around the world AI governance frameworks, and the desire for digital sovereignty are driving operators to localise workloads and expand regional interconnects. In Europe, for example, the combination of the EU’s AI Act and data residency obligations is prompting hyperscalers to build sovereign cloud regions linked by high-capacity, compliant DCI routes. In the US, hyperscalers are scaling out into secondary metros such as Phoenix, Columbus, and Dallas to access renewable energy and lower costs — a shift that demands dense, low-latency interconnect fabrics to maintain the same level of performance as traditional coastal hubs. Together, these trends signal a clear direction: DCI is no longer a uniform global backbone but a blend of regional fabrics, shaped by policy, energy and demand distribution.
Underpinning all of this is a heightened focus on resilience, as AI increasingly supports mission-critical workflows where even brief network failures can disrupt outcomes. Services that rely on continuous model synchronisation, such as real-time translation or autonomous systems demand uninterrupted connectivity. STL Partners’ research shows that operators increasingly regard redundancy via multi-route connectivity (either through the same vendor or through multiple vendors) as essential, not optional. Consequently, operators are increasingly looking at mesh architectures and dark-fibre capacity that can be lit or upgraded quickly to support traffic bursts, as well as provide additional paths for resilience.
DCI is becoming a core component of how AI workloads are distributed and managed across locations. Future data centre infrastructure will depend on DCI networks that can move data efficiently, securely and in compliance with regional requirements.
Conclusion
As AI reshapes the digital landscape, connectivity has become the true determinant of performance and scalability. Power and compute remain essential, but it is the network fabric — both within and between data centres — that defines how fast and how far organisations can go. Inter- and intra-DC networks remain distinct, but AI is increasing the performance demands on both and making their coordination more critical.
For data centre developers and operators, this means embedding connectivity into their core design philosophy. AI-ready facilities will integrate high-capacity optical links and low-latency fabrics. Operators and developers must ensure that they are able to provide the infrastructure for tenants to connect their scale up and scale out networks effectively for consistent high performance.
For telecom and infrastructure providers, DCI evolution represents a chance to move up the value chain. As data centres seek flexible, high-capacity interconnects, telcos that offer programmable, software-defined transport and Network-as-a-Service (NaaS) models will become critical partners in enabling seamless data movement across regions and ecosystems.
For investors, the future value of infrastructure assets will increasingly hinge on connectivity density, diversity, and automation. Facilities with resilient mesh topologies and access to rich fibre ecosystems will command a premium in an AI-driven market. Data centres that underinvest in connectivity will struggle to support high-value AI workloads, which could limit returns.
STL Partners works with data centre operators, telcos, and investors to build connectivity strategies that align with this next wave of infrastructure evolution, helping clients future-proof assets, monetise emerging capabilities and build the digital backbones that will power AI-driven economies.
Looking for advisory services in data centres? Schedule a call.
Download the data centre insights overview pack
Download the data centre insights overview pack
Get a concise, practical summary of the data centre market: the impact of AI and sovereign strategies, the differentiators that win in a crowded landscape, and proven frameworks for market entry, channel partnerships and customer acquisition—backed by case studies and sample deliverables.

Five things we learned at Datacloud Global Congress 2026
We were at Data Cloud Congress 2026 in Cannes last week to evaluate the key narratives among data centre operators, investors and vendors.

The hidden economics of liquid-cooled data centre retrofits
This article, kindly supported by Airedale, explores when liquid cooling retrofits make commercial sense, showing why the decision depends on HPC pricing, facility fill, market constraints and disciplined execution.

Key takeaways from the launch of the Quantum Infrastructure Council
STL Partners attended the launch of QIC to explore what it will take to deploy
quantum technologies in real-world data-centre environments.
Five things we learned at Datacloud Global Congress 2026
We were at Data Cloud Congress 2026 in Cannes last week to evaluate the key narratives among data centre operators, investors and vendors.
The hidden economics of liquid-cooled data centre retrofits
This article, kindly supported by Airedale, explores when liquid cooling retrofits make commercial sense, showing why the decision depends on HPC pricing, facility fill, market constraints and disciplined execution.

Modular data centres: can prefabricated design speed up construction?
A look at whether modular data-centre design can help operators deliver capacity faster, scale more flexibly and respond to rising demand.