
Download
Listen
Explore our AI-RAN hub

AI-RAN has become one of the hottest topics in telecoms, attracting significant attention and investment across the ecosystem, from operators and network equipment providers to chipmakers. In this article, we delve into different architecture and investment considerations for operators as the industry emphasis shifts from AI-RAN as a concept to a commercial reality.
Introduction
AI-RAN represents a significant opportunity for operators looking to modernise and monetise their radio access network (RAN) infrastructure. This is evident from NVIDIA’s recent $1 billion investment in Nokia in October 2025 to accelerate AI-RAN innovation. However, AI-RAN should not be viewed as a single upgrade or uniform architectural shift. The term is currently used to describe three distinct deployment approaches, each with different technical requirements, investment implications, and commercial rationales. These approaches vary in their objectives, the degree of architectural change required and the extent to which they alter the role of the RAN within the broader network and compute environment.
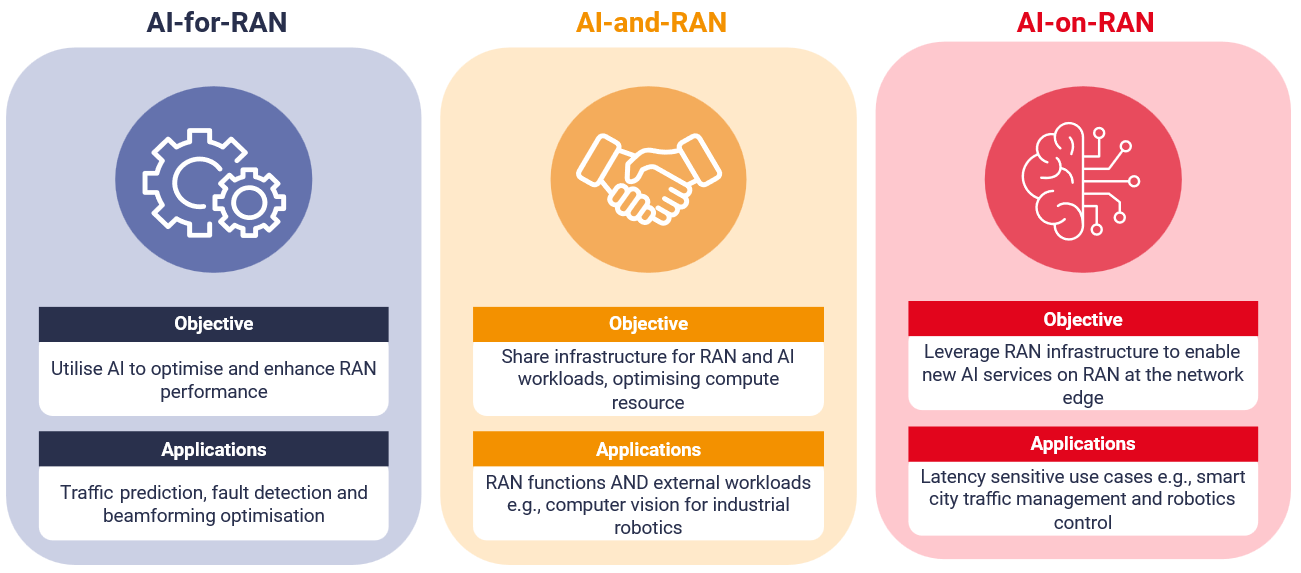
Three primary AI-RAN deployment models are:
- AI-for-RAN: the application of AI techniques to optimise RAN performance, efficiency and automation.
- AI-and-RAN: the deployment of shared infrastructure capable of supporting both RAN workloads and general-purpose AI workloads.
- AI-on-RAN: the use of RAN infrastructure as a distributed compute platform to host AI-enabled applications and services.
These models are not mutually exclusive, but they imply different priorities and infrastructure decisions. For operators, understanding the differences between these models is critical. This article explores the infrastructure implications of each AI-RAN deployment model.
Figure 1: Three AI-RAN deployment models
Source: STL Partners
AI-RAN architecture: Where to start?
AI-RAN introduces a materially different cost and infrastructure profile compared to traditional RAN deployments. Unlike conventional RAN functions, AI workloads – particularly those involving real-time inference or unstructured data processing – are significantly more resource intensive. This drives additional capex in the form of GPUs or other accelerators, higher memory bandwidth, and high-speed interconnects. It also increases opex through higher power consumption, cooling requirements, space constraints, and ongoing system maintenance. For many operators, these combined pressures make large-scale AI deployment in the RAN financially and operationally challenging.
The three AI-RAN models imply different compute footprints and architectural complexity.
- AI-for-RAN, where AI supports internal RAN and network operations with a smaller GPU footprint, inference placed in the CU, near the RIC or in a limited number of RAN sites and training mostly centralised.
- AI-and-RAN, where RAN infrastructure hosts both RAN and external workloads. This increases the GPU and platform footprint and introduces stronger orchestration and automation requirements, often including multi-tenancy style resource partitioning and isolation so AI workloads can coexist with RAN functions without impacting performance.
- AI-on-RAN, where RAN infrastructure becomes a marketplace grade platform for external workloads meaning compute and platform operations scale materially from the AI-and-RAN deployment model. Inference and application runtime are deployed widely across RAN sites alongside RAN functions, with a much larger GPU footprint and added platform layers for multi tenancy, isolation, orchestration, developer enablement, and governance.
These architectural differences are reflected in accelerator strategy. Entry-level inference deployments may be supported by lower-cost GPUs such as NVIDIA’s L4 (approximately USD 4,000), enabling a “start small” approach aligned with AI-for-RAN use cases. By contrast, more demanding AI-and-RAN or AI-on-RAN scenarios – particularly those involving large-scale model training or high-performance AI processing – may require significantly more powerful platforms such as NVIDIA’s Grace Hopper or Blackwell, which can exceed USD 125,000 per unit.
In practice, this reinforces a tiered compute model: CPUs continue to handle orchestration and standard RAN processing, while GPUs or other accelerators are introduced selectively for AI-specific workloads. The scale and performance tier of those accelerators vary according to the deployment model and associated commercial ambition.
Capital expenditure across AI-RAN deployment models
Across the three models, it is useful to consider the investment implications of different AI-RAN deployment architectures. As part of our research to assess the commercial viability of AI-RAN, we modelled three deployment strategies using a representative medium sized operator with annual revenues of USD 7.5 billion and a network of 15,000 cell sites. The objective was to estimate how much financial benefit each scenario must generate over ten years to break even by year six. To estimate the investment required for each deployment model, we modelled different compute configurations, varying the mix of CPUs and GPUs to reflect the expected intensity of AI workloads in each scenario.
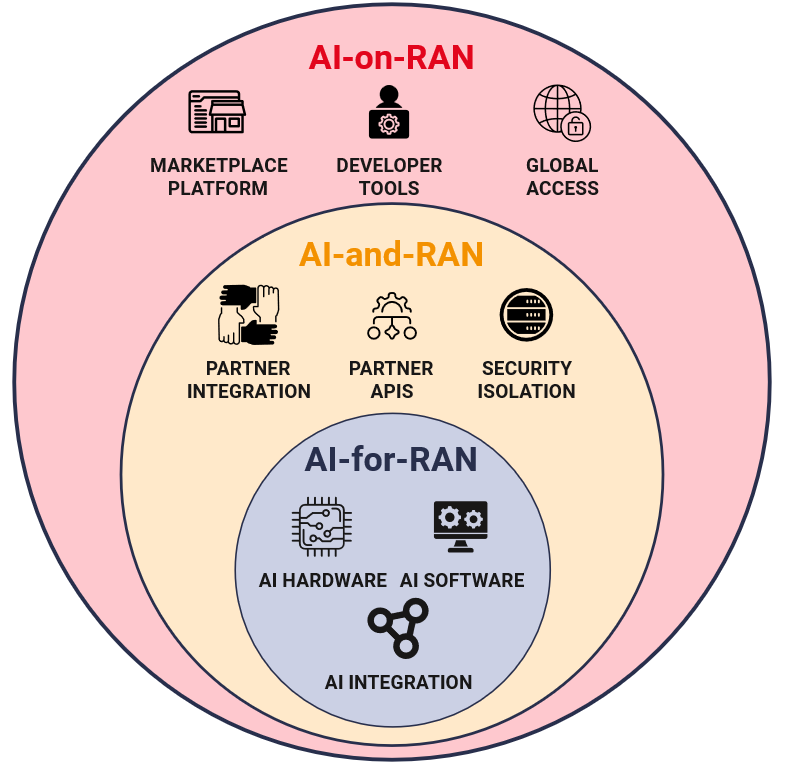
As integration between AI and RAN deepens, demand for accelerated compute rises and so does capital expenditure. This creates a clear capex gradient: AI-for-RAN requires the least incremental investment, AI-and-RAN sits in the middle, and AI-on-RAN is the most capital-intensive due to its reliance on substantial distributed GPU capacity. Importantly, these models are not isolated: AI-on-RAN builds on the AI-and-RAN architecture which, in turn, stands on the shoulders of the AI-for-RAN infrastructure. Foundational investments in acceleration-ready infrastructure, orchestration, and security can be reused and extended as operators progress along this path.
In our modelling, this capex gradient reflects the economics of accelerator-based infrastructure. While higher-performance GPUs can reduce the number of servers required to deliver a given workload, GPU-equipped servers typically cost around 2.5 times more than CPU-only servers. As a result, deeper levels of AI integration increase not only compute density but also server-level capital intensity. The overall cost impact therefore depends on the mix of workloads, utilisation rates, and the scale of deployment. In other words, the business case improves if operators can drive higher utilisation from the same GPU footprint by stacking internal network AI use cases first, then sharing that capacity with additional AI workloads, and only then expanding into marketplace style external services (by which time market demand is more likely to be proven). This derisks investment: no need for upfront investment on a moonshot.
Across all three models, however, unit costs decline over time as deployments scale, hardware efficiencies improve, and supply chains mature, partially offsetting the higher initial investment required for deeper levels of integration.
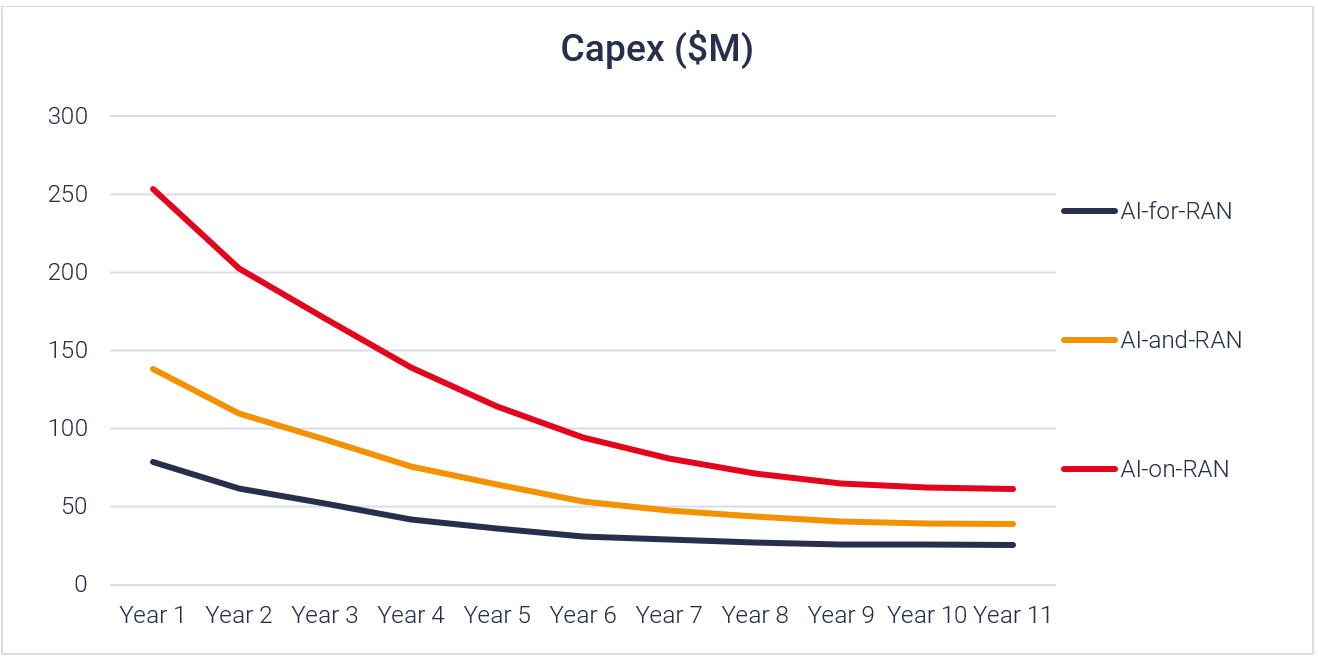
Figure 2: Capital Expenditure ($M) across three AI-RAN deployment models
Source: STL Partners
In AI-for-RAN deployments, capex is driven mainly by edge hardware and integration. In our modelling, this starts at $79M in year 1, then steps down as the initial build is completed, reaching $42M by year 4 and flattening to around $26M by year 10. Operators face upfront spend on AI specific software development and licences, incremental integration of AI into the network, and additional security architecture, with these software and security costs typically front loaded and then shifting into maintenance over time.
AI-and-RAN builds directly on the AI for RAN foundation but requires additional investment as the infrastructure must now support multiple workloads sharing the same platform. This introduces multi-tenancy requirements such as tenant isolation and resource partitioning, as well as extra management layers including configuration management, orchestration, automation, and service management to run the environment securely and reliably. Owing to these added capabilities, capex begins at $138M in year 1, falls to $76M by year 4, and tapers to $39M by year 10.
In AI-on-RAN deployments, the operator is effectively building a marketplace grade platform to host external workloads and serve developers, driving a much larger compute footprint and higher platform investment. Capex peaks at $254M in year 1, declines to $139M by year 4, and still sits at $62M by year 10, remaining materially higher than the other two models. This deployment builds on AI-and-RAN by adding new requirements such as developer tools and onboarding, marketplace and billing functions, and stronger access controls, governance, and compliance.
Overall, these capex profiles reflect a layered progression rather than three standalone choices. These synergies, and the way each model nests within the next, are illustrated in the following graphic:
Figure 3: Capex considerations across three AI-RAN deployment models
Source: STL Partners
AI-RAN: Real world examples
To ground these deployment models in reality, two early proof points help demonstrate how operators are already experimenting with different processors and platform choices:
- SoftBank’s AITRAS is a converged AI and RAN platform built on NVIDIA accelerated infrastructure, with rollout planned from 2026. In its disclosed architecture, SoftBank and partners have implemented CU functions on the NVIDIA Grace CPU Superchip for C RAN style deployments, while also completing a D RAN configuration where CU and DU functions run together on an NVIDIA GH200 Grace Hopper Superchip.
- T- Mobile has taken a test bed approach through its AI-RAN Innovation lab in Bellevue, set up with NVIDIA, Ericsson and Nokia to develop and trial AI-RAN capabilities, with field evaluations also expected in 2026. T-Mobile have described the NVIDIA’s AI Aerial platform as foundational for simulation, training, and deployment workflows around AI-RAN. The group’s stated ambition spans both AI driven network optimisation and exploration of hosting third party workloads on AI equipped base stations.
Figure 4: Real world AI-RAN deployments

Source: STL Partners
What’s the next step for operators?
In conclusion, the architecture and investment profile of AI-RAN varies materially by deployment model. AI-and-RAN and AI-on-RAN typically require larger upfront capital commitments, while a telco-centric AI-for-RAN model can progress with a lighter compute footprint, since many RAN optimisation use cases do not need the latest high-end GPUs and can often run effectively on CPUs. The three models build on each other, and the cost gradient is clear, leaving a viable path that emerges for operators beginning with AI-for-RAN and evolving to AI-on-RAN. Telcos can benefit from starting small, strategically investing into architecture and models aligned with their AI-RAN strategies for telco-centric use cases like traffic optimisation and fault prediction before scaling RAN infrastructure to support external third-party workloads, unlocking AI services-driven monetisation opportunities and new revenue streams for telcos.
Are you looking for advisory services in AI-RAN
Download the AI-RAN market overview
Download the AI-RAN market overview
AI-RAN is shifting from hype to practical strategy. This overview pack explains what AI-RAN is, why it matters now, and how operators can capture value.

Next phase of AI-RAN: Solving operational challenges to unlock new opportunities
AI-RAN is rapidly evolving from a network optimisation technology into a platform for new revenue generation.

Quantifying the revenue and cost benefits from implementing AI-RAN
This article quantifies the revenue and cost benefits across three models – AI-for-RAN, AI-and-RAN and AI-on-RAN – and shows how value scales as new service layers are added.

An insight into the future of AI-RAN
Discover insights from our recent interview with Dr. Alex Jinsung Choi on the AI RAN Alliance’s vision, drivers of RAN evolution, and how AI RAN tackles key industry challenges.

What is physical AI? Definitions, examples and implications for private networks
The term physical AI refers to the transition of AI from the mostly digital sphere into more real-world scenarios and physical processes.

How AI can accelerate IT and OT convergence to transform customer experience
AI can play a central role in enabling convergence, acting as a unifying intelligence layer across IT and OT.
Edge computing at MWC 2026
In contrast to previous years, when edge computing had drifted somewhat to the periphery of the agenda, it was more prominent at MWC 2026, with discussions and demonstrations across the Fira reinfo…